


“Advancements in two fields — programming languages and cloud infrastructure — will converge in a single paradigm: where all resources required by a program will be automatically provisioned, and optimized, by the environment that runs it.” - Shawn Wang
The responsibilities of developers continue to expand; where they previously began and ended at writing application code, they now require in-depth knowledge of cloud application architecture, infrastructure, build and deployment, and more. As a result, developers have an increased need to communicate and collaborate with their operations counterparts. With these expanded responsibilities comes increased complexity, which slows down application development and worsens the developer experience.
In an effort to mitigate these downsides of the serverless era, cutting-edge teams are beginning to use self-provisioning runtimes. The idea behind a self-provisioning runtime is to solve for infrastructure, build and deployment challenges of modern development by automating easily repeatable activities including resource provisioning, granting permissions and configuring policies.
What is a self-provisioning runtime? Self-provisioning runtimes make it possible for developers to declare within their application code the resources they need and how they intend to use them. The self-provisioning runtime then infers from the application code the infrastructure, policies and permissions needed at runtime, which enables them to automate cloud resource provisioning and permission and policy configuration.
Basically, let developers focus on what they do best: writing application code.
The need for automation
In the past, when infrastructure requirements were relatively simple, development and operations teams could get away without automation. Applications were self-contained and ran on a single application server requiring minimal hardware configuration (e.g. CPU cores and scale was accomplished with server replication/load balancing).
With the shift towards distributed systems and managed cloud services (topics, queues, API gateways, functions, etc.) the infrastructure requirements have become significantly more complex and directly tied to the application architecture.
Here is a highly simplified serverless architecture diagram for a product inventory API.
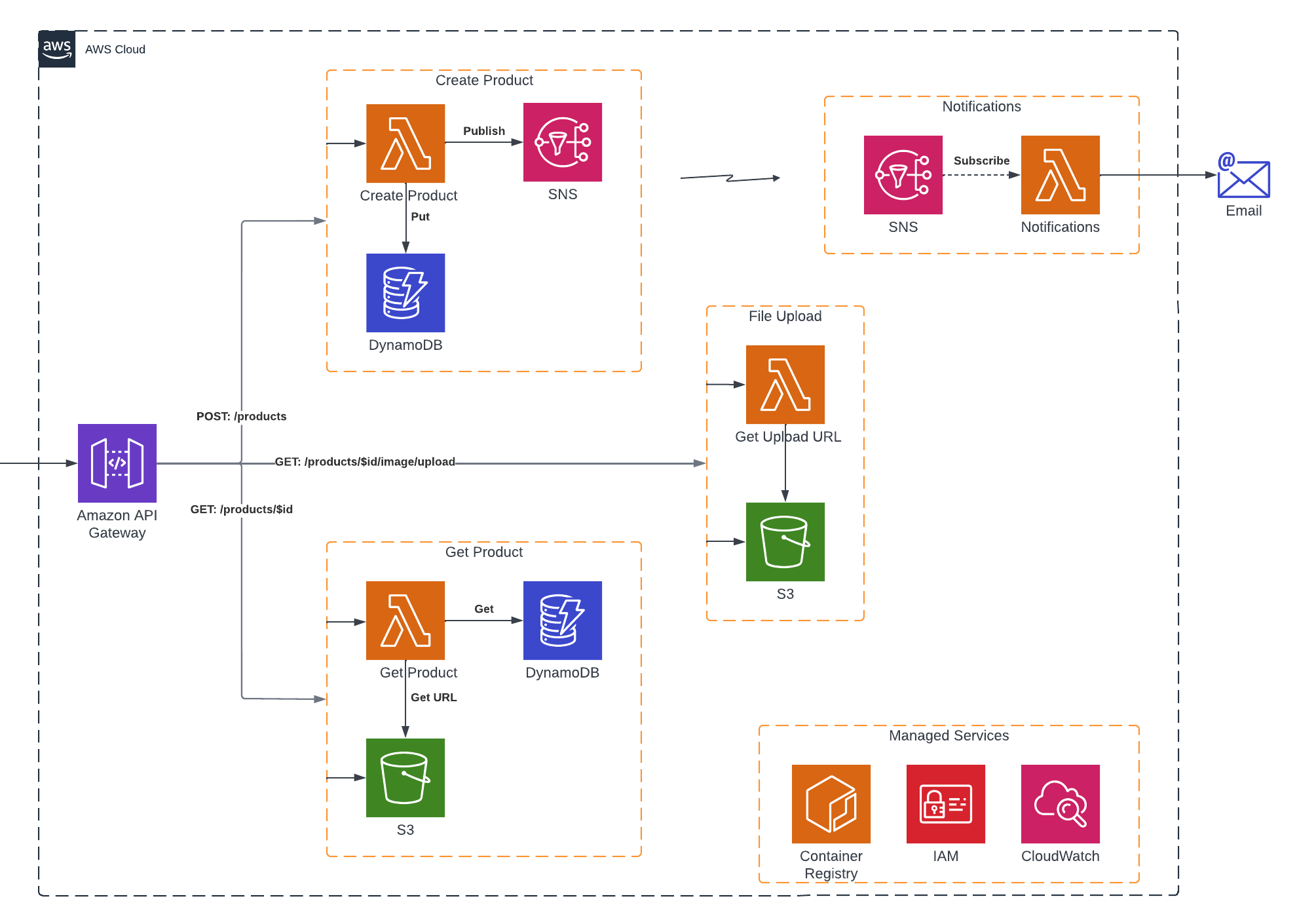
The application code is broken up into 3 separate functions – Create Product, File Upload, Get Product – each of which needs access to managed resources such as databases, buckets, and messaging. Shifting the responsibility of this functionality to the managed services allows developers to work with the latest and greatest, but now requires them to have intimate domain knowledge about how these services work, as well as work with an operations team to understand how to provision and manage these resources.
Instead of requiring development teams to have this in-depth knowledge of cloud services and continually repeating steps to build, deploy and provision infrastructure, automation can take over to free up both developers and operations time.
Bridging the developer/operations communication gap
Automation may also be the key to bridging the communication gap between developers and operations.
In the world of DSLs, the link between code and infrastructure is made via names or resource identifiers (ARNs, etc). This is a brittle relationship as it does not clearly communicate how the application code intends to use the resource – e.g. will it read, write or delete items from a bucket – which makes it difficult for operations to write the correct YAML configuration for the application to run.
To resolve this, developer and operations teams must discuss the requirements for specific resources so that operations can provision and configure the right infrastructure, which becomes a time-consuming process prone to errors.
The outcome of these discussions is generally static YAML that then needs to be tested, debugged, and maintained over time. Here’s a Terraform example provisioning a simple API gateway, which is over 100 lines of code to manage. This looks and acts like code, but it’s missing many guardrails of software development including type safety, native auto-suggest (without DSL specific plugins), unit and integration testing and library/package support.
Instead of trying to find workarounds for verbose provisioning scripts, let's imagine that the applications themselves could dynamically communicate the needs of resources and the correct infrastructure could be generated automatically, without the manual steps teams take today.
Which brings us back to self-provisioning runtimes and the benefits they bring to developer productivity and experience by way of automation. Shawn Wang created a great blog post describing self-provisioning runtimes as the holy grail of serverless and inspired us to create this diagram illustrating the power they bring to cloud development.
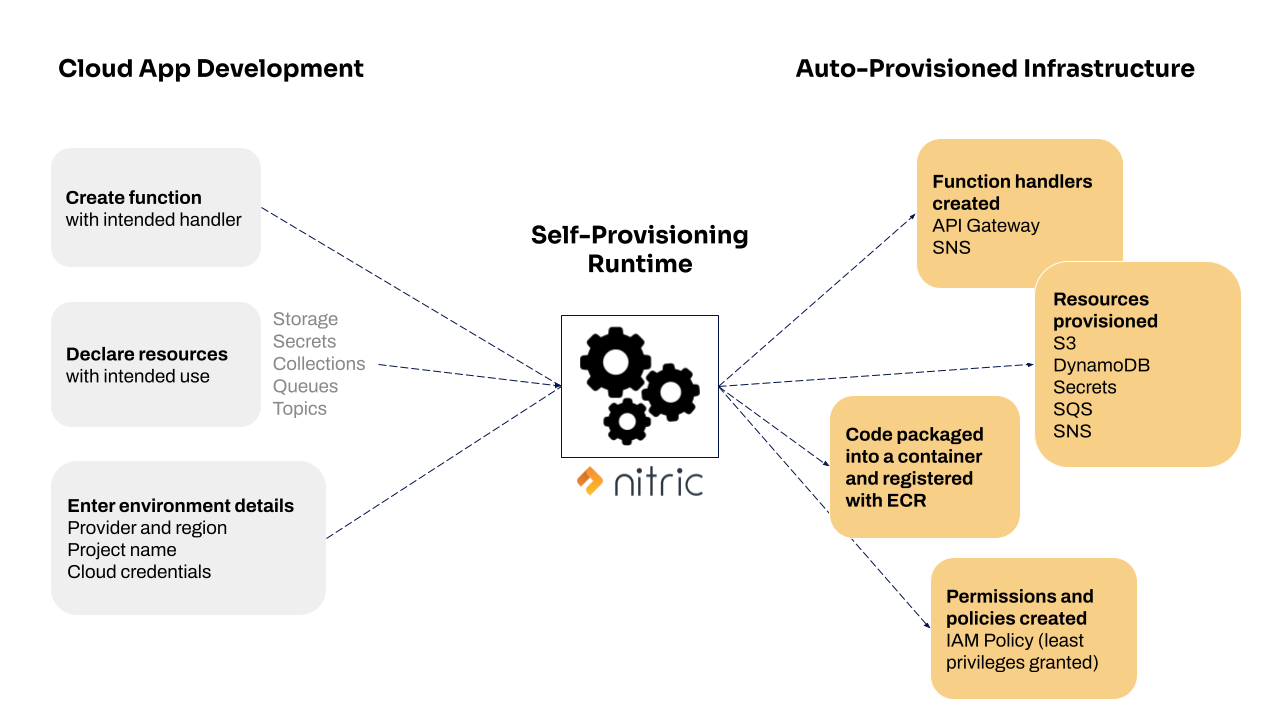
Let’s take a look at how this works in practice.
Nitric’s self-provisioning runtime
Self-provisioning runtimes allow developers to clearly indicate their intended use of a resource, as in this code snippet:
import { schedule, bucket } from '@nitric/sdk';
// A bucket resource, which only has delete permissions
const assets = bucket('assets').for('deleting');
// A schedule that cleans up files in a bucket every 3 days
schedule('cleaning-day').every('3 days', async (ctx) => {
const files = await assets.files();
await Promise.all(files.map(file => file.delete()));
}
);
From this code we can see that the intended use of our resources is clear. We have:
- A function which we have defined inline which runs on scheduled interval of 3 days
- A bucket named ‘assets’ which allows its file contents to be deleted
The Nitric framework encapsulates the domain knowledge required to infer resource details directly from the code and take care of the provisioning and deployment of all resources, policies, and permissions.
Not only does this automation reduce manual work, it also provides an unsung benefit by establishing a high level of consistency. Being able to trust that the infrastructure will be deployed predictably across all teams and projects is invaluable to managing security risks and staying on top of compliance and regulatory challenges. Without automation, this is a substantial challenge when development teams change, scale horizontally or face increased security requirements.
In 2021 I read another great blog post by Erik Bernhardsson, who challenged the community to push boundaries with his serverless wishlist, concluding with a simple pointed question: ‘Can you imagine a world without YAML?’
We’ve taken a giant leap forward in pursuing this vision with automation that eliminates the need for verbose YAML configuration describing infrastructure. As a result, we’re also eliminating the inevitable communication breakdowns between developers and operations that occur when it’s time to get your project live.
Here's what configuration looks like with Nitric. YAML configuration is limited to the basics, such as project name and target environment.
nitric.yaml
name: project-tidy
handlers:
- functions/*.ts
env.yaml
name: aws-development
provider: aws
region: us-east-1
Nitric is an Open Source framework listed on the CNCF Serverless Landscape. It’s used by teams to simplify cloud-native development and deployment to AWS, GCP, and Azure. We’re actively developing and seeking feedback from the community to drive innovation.
Try out the Nitric framework and let us know what you think.

