


With our earliest versions of the Nitric framework, we focused on making it easy to develop cloud-native applications that could be deployed to any cloud from a single codebase. We leveraged Infrastructure as Code (IaC) tools to provision cloud infrastructure, taking advantage of the automation and repeatability benefits they provide. As we began to code with Nitric, however, we realized we were still spending a lot of time on tedious, repetitive infrastructure configuration.
The original approach
Initially, the Nitric framework used a nitric.yaml file, allowing users to define their application's infrastructure separate from their code.
Developers would reference the resources in their nitric.yaml file by name in their application code.
This was made possible by IaC: we had evaluated IaC tools including Terraform and Pulumi and had chosen Pulumi for implementing our infrastructure providers.
Dogfooding our own tech

The initial design was a huge improvement on what we'd used to build cloud-native apps in the past. The tech was ready to go, so it was time to build with it and enjoy how much easier our hard work was going to make the future of application development.
Our new project started with a CRUD API, simple enough right? Write some basic HTTP handlers, wire in some resources like buckets and collections, then define the API with a standard approach like OpenAPI. Easy... or so we thought.
Wiring up resources
As stated above, every project included a nitric.yaml file describing how a Nitric project was to be deployed. The file included names for resources and the handlers for serverless functions:
name: my-project-name
functions:
example-function:
handler: functions/example.ts
collections:
example-collection: {}
queues:
example-queue: {}
buckets:
example-bucket: {}
topics:
example-topic: {}
api:
example-api: {}
The resources could then be referenced in code, using their name and our SDKs:
import { faas, storage, eventing, collections, queues } from '@nitric/sdk'
const topic = eventing().topic('example-topic')
const collection = collections().collection('example-collection')
const queues = queues().queue('example-queue')
const bucket = storage().bucket('example-bucket')
faas.http(async (ctx) => {
// your logic here
})
Without going into a full example, this approach lead to a few pain points:
- It was error prone, especially to typos
- Refactoring resources was challenging
- Definitions were always duplicated, in the yaml and again in the code
Additionally, we also had to define our APIs using OpenAPI specs.
Defining the API
The project started out defining a simple CRUD API with a few models to handle, not massive but not small either.
Functions in our application would be wired via an API gateway, defined in the spec using an operation level OpenAPI extension like so:
x-nitric-target:
name: my-function
type: function
The problem with these specs was that OpenAPI is quite verbose, even for simple schenarios. So, 700 lines of API spec later, we'd had enough! It was starting to become unwieldy and prone to errors for simple changes and just plain hard to look at.
This isn't a criticsm of OpenAPI, but of our approach. There are generally two schools of thought when it comes to building out contract driven APIs and that is you either:
- write specs first and generate code from the spec; or
- write code first and generate your spec from the code.
Our approach was the worst of both. Hand written specs, wired to hand written functions, without assistive generation for the server-side code in-between.
The irony of this realisation is our core tech uses gRPC which exemplifies the first of the above approaches...
This realizaton lead us down the path of revisting the approach, ultimately revamping the Nitric framework in the process.
A new approach, enter configuration as code
We decided to bring our configuration into our code, removing the issues caused by their separation. This is not in the same way that many CDK solutions work today, where application and infrastructure are both written in code but remain separate.
Instead, we wanted a framework that allows developers to expressively communicate the cloud infrastructure requirements of their application using common cloud concepts like topics, queues, storage etc. We wanted to take the advantages of IaC and go another step further to improve the developer experience.
It started from the idea that developers could simply declare and use cloud resources, directly within their applications:
import { topic, api, collection } from '@nitric/sdk'
const exampleApi = api('example')
const exampleBucket = bucket('example').for('writing')
const exampleTopic = topic('example').for('publishing')
exampleApi.post('/example', async ({ res }) => {
// your logic here...
})
It was immediately obvious this approach addressed most of the developer experience concerns we had with the original:
- resources are defined in a single location
- refactoring can be done with existing tools and IDEs
- resources can be shared across functions using existing module and dependency systems
As an added bonus, we were now able to declare resources with intent allowing us to implement least-priveledge security practices, something that was proving to be a challenge with our first approach.
Comparing it with our previous approach
Prior to the implementation of our configuration as code we would need to define:
- A
nitric.yamlfile, containing:- function defintions for the application, and
- API definitions that pointed to OAI3 specs
- An OAI3
api.yamlfile that defined the API and pointed at the functions defined in ournitric.yaml - The code that defined the functions
This doesn't sound like much, but you can see from this "Hello World" example it can be a lot, even for a basic use case:
nitric.yaml
functions:
hello: functions/hello.ts
apis:
hello: api.yaml
api.yaml
openapi: '3.0.0'
info:
title: Hello World
version: '1.0'
paths:
/hello:
get:
summary: Say hello
description: An endpoint that generates greetings.
operationId: hello
responses:
200:
description: greeting response
x-nitric-target:
type: function
name: hello
functions/hello.ts
import { faas } from '@nitric/sdk'
faas
.http(() => {
return `hello world`
})
.start()
24 lines just for Hello World, in a non-trivial app your spec alone would more likely be 1000+ lines
The same example with config as code
nitric.yaml
handlers:
- functions/*.ts
functions/hello.ts
import { api } from '@nitric/sdk'
const mainApi = api('main')
mainApi.get('/hello', (ctx) => {
ctx.res.body = 'Hello World'
})
Thats it! The same app, in just 7 lines.
The team found, with non-trivial applications, this approach also scales better than the previous style.
How it works
At first glance this might look like a language parsing problem where software would be needed to read the users code to figure out the resources they were actually using, but Nitric is a bit different in its approach to abstracting the cloud and we used this to our advantage.
When running in the cloud, each Nitric function has a lightweight proxy in front of it that abstracts away the implementation concerns of the cloud that its running on. This server can be anything that conforms to the gRPC API spec, so we built a new resources API and embedded a "deploy-time" server into our CLI.
Here is what we ended up with (using our AWS provider as an example):
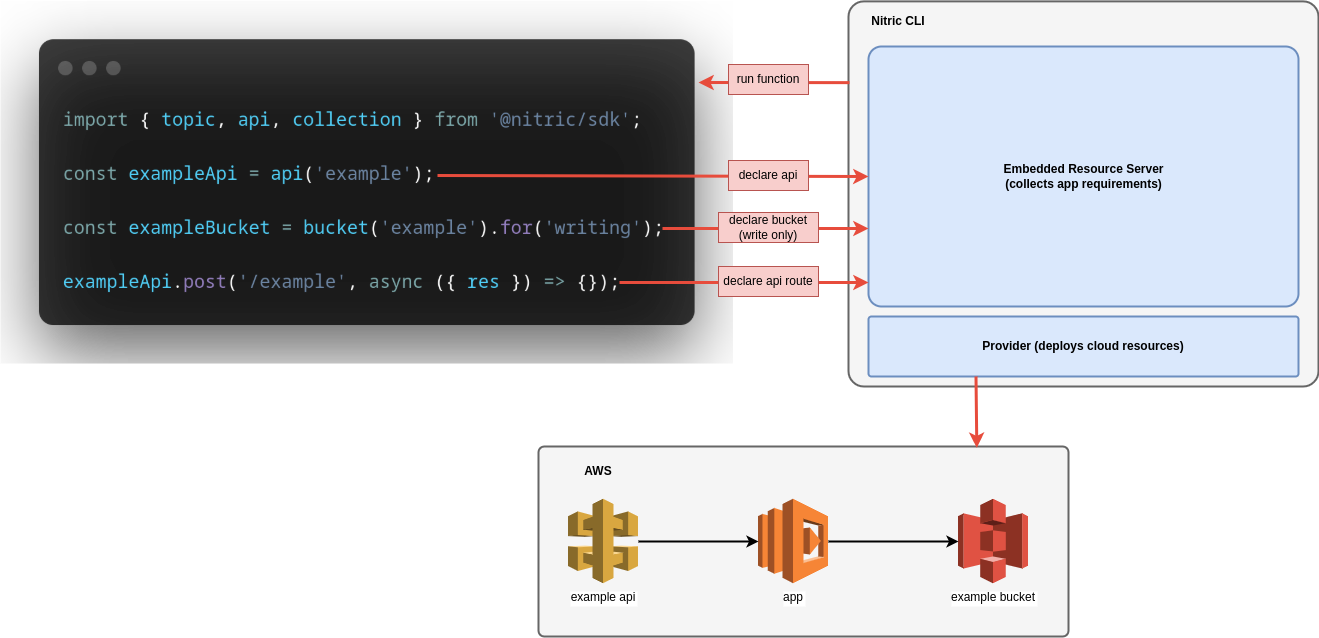
This applies to all the clouds and resources we support today
Our latest Node.js SDK and Nitric server are built on this approach and we're looking forward to broadening our language support as our community grows and requests come in.
Give it a try
See for yourself as well. This video shows what it looks like to build a cloud application with Nitric, and you can easily try building your own project with Nitric.

